高并发可靠服务架构#
构建高并发、高可用的互联网服务时,架构设计不再只是"能跑起来",而是要在海量请求、有限资源、复杂业务链路中,做到低延迟、高吞吐、可扩展、容错强。以下结合典型 BFF + 微服务 + 云原生基础设施架构,进行系统性拆解。
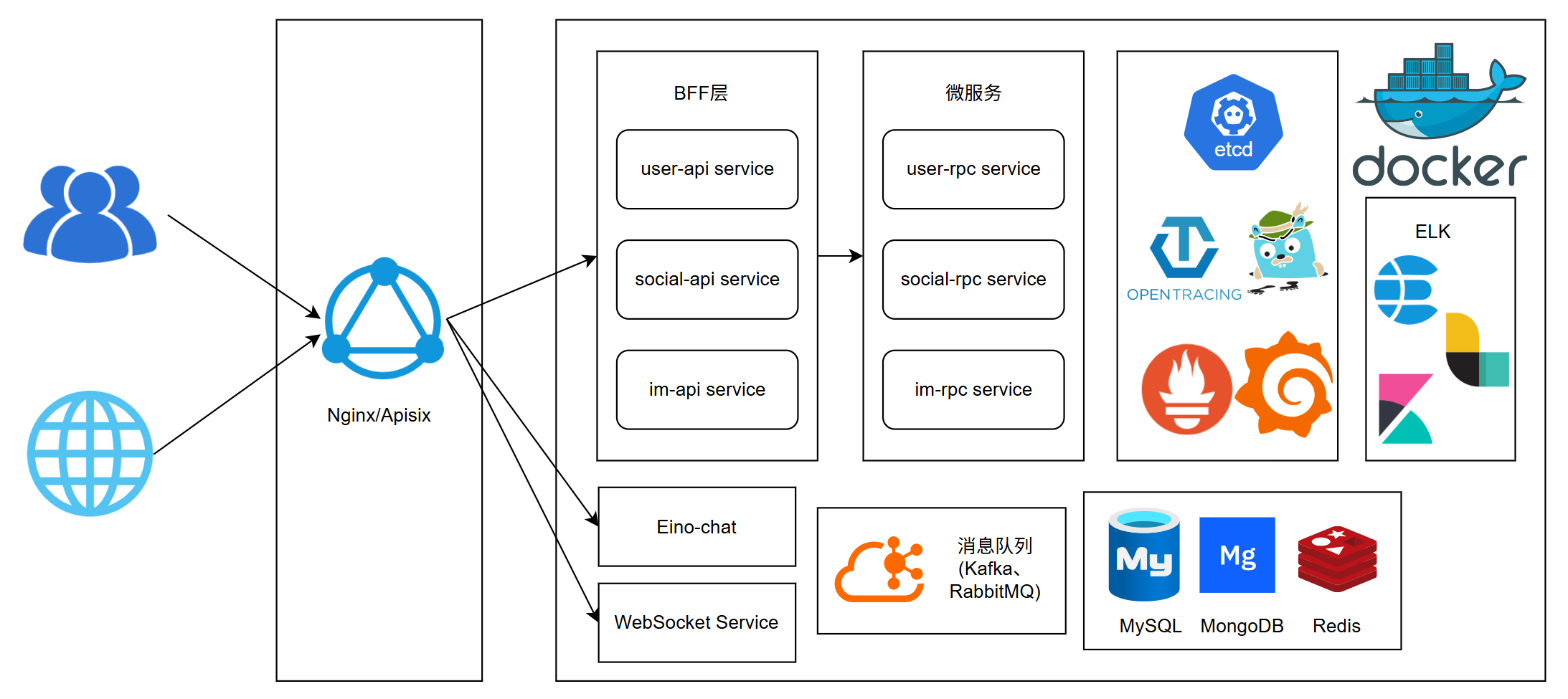
一、架构:分层与分离#
| 层级 | 组件 | 职责 |
|---|---|---|
| 接入层 | Nginx / Apisix | 网关层,流量入口 |
| BFF 层 | user-api、social-api、im-api | Backend for Frontend,数据聚合与协议转换 |
| 微服务层 | user-rpc、social-rpc、im-rpc | 核心原子能力 |
| 基础设施层 | etcd | 服务发现与配置管理 |
| Kafka / RabbitMQ | 消息队列 | |
| MySQL、MongoDB、Redis | 持久化与缓存存储 | |
| WebSocketService | 实时通信 | |
| 可观测性 | ELK + OpenTracing | 日志收集与全链路追踪 |
💡 设计原则:API 层与 RPC 层分离,BFF 负责数据聚合、协议转换、业务编排,RPC 层专注核心原子能力,符合单一职责与高复用。
二、关键组件分析与思考#
2.1 BFF + 微服务 RPC:拆分并下沉热点逻辑#
问题背景:传统单体架构中,一个接口可能调用多个 DB、做大量计算,并发一高,线程池迅速打满。
解决方案:
- BFF 无状态、轻量化,只做聚合与裁剪
- 核心逻辑下沉到 user-rpc / social-rpc
- RPC 层独立扩缩容
⚠️ 注意事项:
- BFF 不是"万能代理",避免在 BFF 中做复杂事务或慢查询,否则会成为并发瓶颈
- RPC 层建议使用批量处理与并行调用(如
/batch_user_info),减少 BFF ↔ RPC 的网络开销
2.2 Etcd:服务发现与配置(非状态存储)#
- RPC 服务地址注册
- 配置动态下发(限流阈值、开关)
- 搭配本地缓存 + 长轮询减少 etcd 读压力
2.3 Redis:高并发读写关键缓冲层#
核心用途:
- 热点数据缓存(用户信息、关系链)
- 分布式限流(令牌桶、漏桶)
- 分布式锁(防止重复写)
- 计数器(点赞、在线人数)
常见瓶颈与优化:
| 问题 | 优化策略 |
|---|---|
| 大 key / 热 key | 拆分 key、本地缓存提前挡 |
| 单线程模型 | 避免复杂命令(keys、hgetall) |
| 持久化开销 | 高并发场景建议关闭 RDB/AOF 或使用副本实例 |
2.4 消息队列:削峰填谷,解耦非实时链路#
典型场景:
- IM 消息扩散:发一条消息 → MQ → 异步推送给多个接收者
- 日志/审计:异步写入 ES(ELK)
- 社交动态推送:粉丝数大时不能同步写,必须 MQ 削峰
注意事项:
- 明确哪些链路必须可靠(订单、IM 历史) → MQ + 落库
- 哪些链路允许丢失(点赞通知) → RabbitMQ 提升吞吐
- 必须监控 MQ 积压,否则高并发下会演变为隐性的"慢链路"
2.5 WebSocket:长连接与并发瓶颈#
问题背景:
- 单机长连接上限
- 内存占用过高
- 广播风暴
优化策略:
- 使用连接迁移(发布时通过 etcd 定位用户在哪台 WebSocket 节点)
- 消息推送不走 WebSocket 节点直接 DB,而是通过 MQ + 路由表
- 长连接服务本身无状态化(session 存 Redis 或本地内存 + 一致性哈希)
三、高并发核心设计模式#
在组件选型之上,真正支撑高并发的是一套可复用的设计模式。以下三种模式在本架构中反复出现。
3.1 最终一致性 vs 强一致#
| 模式 | 适用场景 | 实现方式 | 性能代价 |
|---|---|---|---|
| 强一致 | 订单扣减、账户转账 | 分布式锁 + 事务(Seata TCC) | 极高,吞吐下降 80%+ |
| 最终一致 | 点赞数、评论数、动态推送 | 本地消息表 + MQ + 定时对账 | 低,可支撑 10 倍并发 |
💡 核心原则:高并发链路优先选择最终一致性。强一致只留给真正不可妥协的场景(如支付)。
3.2 缓存与数据库一致性方案#
高并发下缓存与 DB 的一致性是经典难题。本架构采用旁路缓存 + 异步清理模式:
写请求:
1. 更新 DB
2. 发送 MQ 消息(记录被更新的 key)
3. 立即返回成功
异步清理:
1. 消费者从 MQ 拉取消息
2. 删除 Redis 中的对应 key
3. 下一次读请求触发缓存重建为什么不是更新缓存?#
高并发下直接更新缓存会引入严重的竞争条件。考虑以下场景:
时刻1:请求A读取缓存(miss),从DB读取值 X=100
时刻2:请求B更新DB,将X改为200
时刻3:请求B更新缓存,设置X=200
时刻4:请求A更新缓存,设置X=100(覆盖了请求B的更新)
结果:缓存中X=100,但DB中X=200,一致性被破坏,且无法自动恢复。即使采用"先删缓存"策略,仍存在经典的读写并发问题:
时刻1:请求A读取缓存(miss),从DB读取值 X=100
时刻2:请求B更新DB,将X改为200
时刻3:请求B删除缓存(key被删除)
时刻4:请求A更新缓存,设置X=100(此时缓存仍是旧值)问题依然存在?—— 这就是经典的"读写并发"问题,需要配合延迟双删或版本号解决。
更安全的方案:版本号 / 时间戳#
// 缓存中存储带版本号的值
type CachedValue struct {
Value interface{} `json:"value"`
Version int64 `json:"version"`
}
// 更新时:先写DB,再删缓存,写入前比对版本号
func UpdateWithVersion(ctx context.Context, key string, newValue interface{}) error {
newVersion := time.Now().UnixNano()
// 1. 更新DB(带版本号)
err := db.Exec("UPDATE users SET name = ?, version = ? WHERE id = ?", newValue, newVersion, uid)
if err != nil {
return err
}
// 2. 删除缓存(让下次读重建)
return redis.Del(key)
}
// 读取时:从缓存读取并校验版本
func GetWithVersion(ctx context.Context, key string) (interface{}, error) {
// 1. 从缓存读取
cached, err := redis.Get(key)
if err == nil {
var val CachedValue
json.Unmarshal(cached, &val)
return val.Value, nil
}
// 2. 缓存未命中,从DB读取
var value interface{}
var version int64
db.QueryRow("SELECT name, version FROM users WHERE id = ?", uid).Scan(&value, &version)
// 3. 写回缓存(带版本号)
cachedVal := CachedValue{Value: value, Version: version}
redis.Set(key, cachedVal, 3600)
return value, nil
}3.3 限流、熔断、降级三件套#
| 策略 | 触发条件 | 本架构落地方式 | 效果 |
|---|---|---|---|
| 限流 | QPS 超过阈值 | Nginx 令牌桶 + Redis 滑动窗口 | 拒绝超额请求,保护下游 |
| 熔断 | 错误率 > 50% 或 P99 > 5s | RPC 层集成 Sentinel | 快速失败,不堆积请求 |
| 降级 | 熔断触发或手动开关 | BFF 返回缓存/默认值 | 牺牲次要功能保住核心 |
🔧 配置动态化:限流阈值、熔断开关均通过 etcd 下发,无需重启服务。
四、典型故障与复盘#
4.1 Redis 大 Key 引发雪崩#
现象:某日 20:00 晚高峰,user-api 接口 P99 延迟从 50ms 飙升至 8s,部分请求超时。
根因分析:
- 用户关系链使用 Redis Hash 存储,如某大 V 拥有 2000 万粉丝
hgetall命令一次拉取全部粉丝 ID,导致网络缓冲区溢出- 同一 Redis 分片上其他 key 也被阻塞
4.2 MQ 堆积引发"慢链路传染"#
现象:IM 消息发送成功后,接收方延迟 10 分钟才收到推送。
根因分析:
- 消费者从 Kafka 拉取消息后,需要写入 MySQL 建立索引
- 某次上线引入慢 SQL(未命中索引),单条消费耗时从 10ms 膨胀到 2s
- 生产者写入速度不变,消费速度骤降,积压迅速达到百万级
五、总结#
真正决定高并发能力的,往往不是组件选择,而是:
- ✅ 是否对每个核心链路做了容量评估与压测
- ✅ 是否设计了降级(限流后返回缓存/默认数据)与熔断
- ✅ 是否避免跨微服务的事务(分布式事务在高并发下代价极大)
- ✅ 是否做到**“读写分离 + 最终一致性”**接受
🎯 核心理念:高并发不是"加机器就能解决",而是在设计之初就假设每一个组件都会挂、每一条链路都会慢,然后通过拆分、异步、缓存、限流、降级、可观测性,把不确定性变成可控的系统行为。